
It is not easy to define what Big Data is, or to draw a clear dividing line between what is “big” and “small” data. This difficulty is reflected in the number and variety of conceptualizations that can be found about Big Data in the literature.
Big Data promises exciting new opportunities, including unlocking new insights that can accelerate the creation of new products and services, boost customer relationships, improve operational processes, and even embrace innovative business models. Moreover, Big Data is the perfect companion to traditional “small data”. However, Big Data and all its potential will come to nothing if organizations are not able to understand it, integrate it, analyze it and do something with it. Therefore, a fundamental first step is to begin to understand the true dimension of what Big Data is, for which we are going to review in this article some of the main views that can help transformational leaders to be clear about it.
Feature-centered View
Perhaps one of the most common and widely accepted ways of clearly define Big Data is through the feature-centered view, which characterizes Big Data according to three Vs: volume, variety, and velocity.
Unlike other types of data, Big Data cannot be stored on an ordinary PC or portable hard drive, as it typically exceeds 100 terabytes or even petabytes of information (hence the volume). Big Data emanates from a wide variety of structured and unstructured sources, and can have many formats (e.g., texts, sounds, images, videos). In addition, the data is usually spatially and temporally referenced (variety). Likewise, the speed of data creation and analysis occurs in a very short time, which allows decision-making to be adapted to very short time windows that may lead to the initiation of corrective and/or adjustment actions practically in real time.
But these are not the only characteristics that help us define Big Data. The conceptualization based on the three Vs has been extended several times to accommodate four more “Vs”" (Figure 1):
- Veracity, which refers to the reliability, validity, and completeness of data.
- Value, which highlights the role of Big Data as a tool used to create value for both consumers and firms.
- Variability, because Big Data often consists of unstructured records whose meaning can change depending on the moment and the context.
- Visualization, or the need for the insights obtained from Big Data to be displayed in a visually attractive and understandable way for users so that they can do useful things with them.
Process-centered View
In addition to the feature-oriented view, Big Data can also be defined according to a process-centered view. This approach is based on highlighting the processes that are inherent to Big Data, such as the collection, storage, processing, and analysis of Big Data, and the technologies that support them.
According to this approach, Big Data is the set of data that is difficult to collect, manage, analyze, and visualize in a limited time with the available technologies of today. This entails the need for organizations to implement processes aimed at managing Big Data and technologies that overcome the limitations of traditional technologies.
Big Data Definition Extended
Other characteristics that distinguish Big Data, apart from those mentioned in the feature-centered and process-centered views perspectives, are the following:
- Big Data often collects and explores entire populations rather than samples, thus challenging conventional statistical tools and inferential methods.
- Big Data provides a high level of granularity in the data, which allows the analyst to focus on very fine aspects or very specific qualities of the information available, which can be reflected in finer and more accurate decision-making.
- Big Data can be used flexibly when analyzing different data collections and extracting meaning from them.
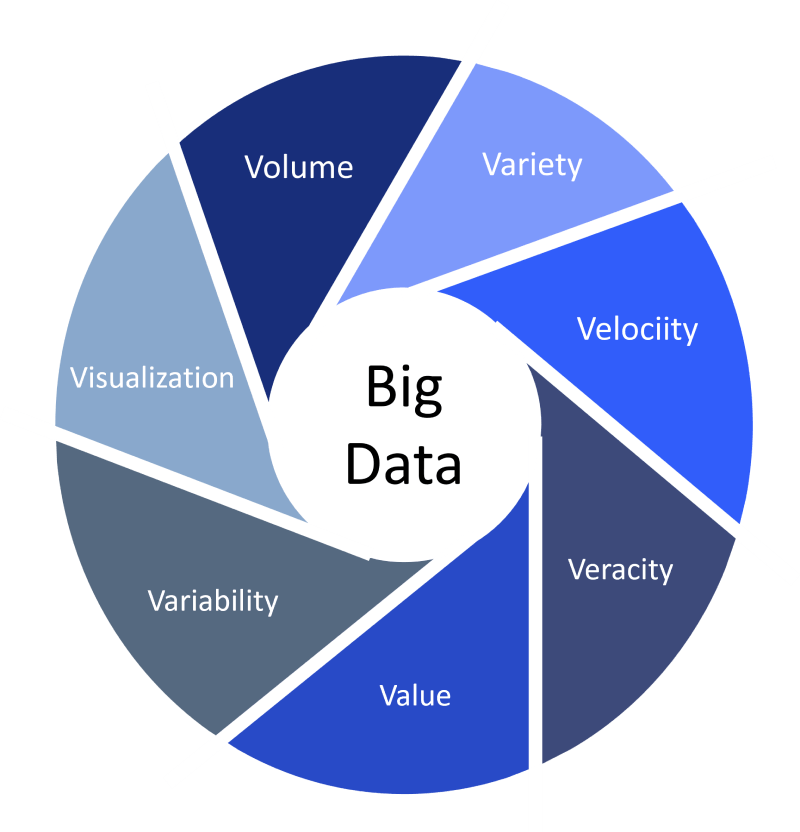
Figure 1: Dimensions of Big Data
Source: Own elaboration
Transformational leaders should keep in mind that when talking about Big Data, we are not only referring to large public or internal transactional structured datasets (e.g., sales, customers, inventories, data from the population register, vehicle registration, etc.), but also peripheral and non-transactional unstructured data generated by sensors, smartphones, and radio-frequency identification (RFID) chips, used to track the dynamics of visitors in a territory or the products in a supply chain, learn about the behavior of consumers and their interactions in social media, or predict trends faster and more accurately.
Finally, Big Data is also synonymous with data analytics and disruptive technologies. Analytics has been around for some time now and has gone through various stages, from the invention of spreadsheets that allowed for simple calculations to today’s sophisticated analytics tools. Data analytics relies heavily on statistical techniques, including both descriptive and predictive modeling, to understand not only “what has happened” but “what will happen”. From a statistical point of view, Big Data analytics allows the identification of patterns, makes predictions, and provides advice for better decisions making (i.e., which products to deliver to customers, or which services to bundle). For their part, Big Data technologies allow complex analytics to be applied to large and highly dispersed data sets, providing very fine granularity and, in essence, leading to accurate decision-making.
Photo by kjpargeter Freepik